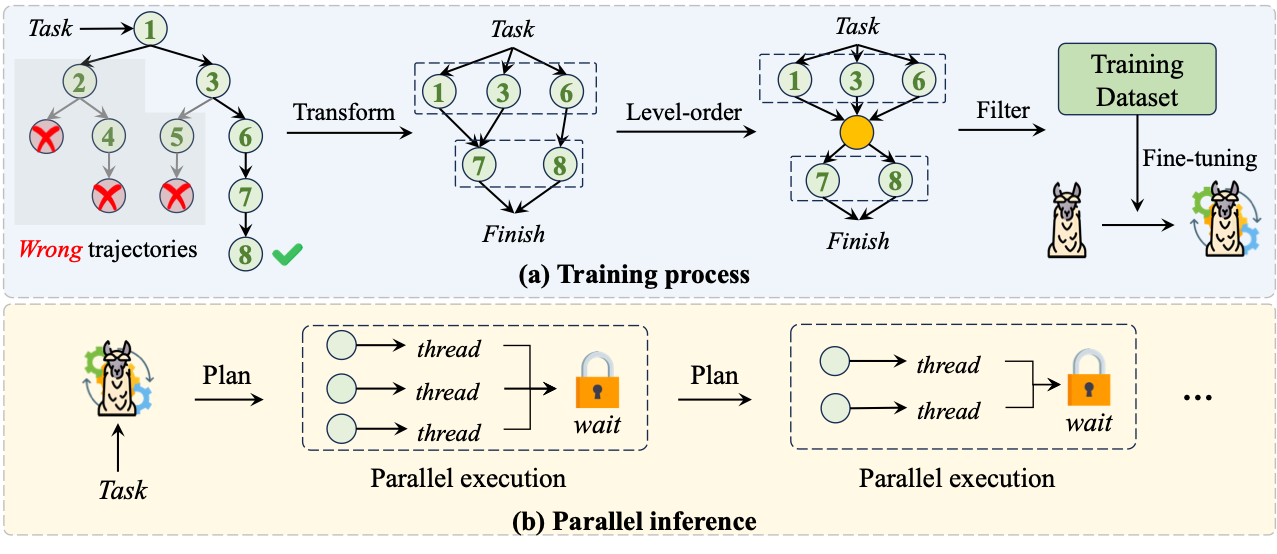
Although current Large Language Models (LLMs) exhibit impressive capabilities, performing complex real-world tasks still requires tool learning. Mainstream methods, such as CoT/ReAct, rely on step-by-step tool invocation to interact with external environments, but they are limited in scope and lack adequate task-planning capability. To address these limitations, other studies introduce the first Search-based Decision Tree (DFSDT), which still suffers from the high computational cost overhead. In this paper, we introduce a novel parallel tool invocation paradigm, DTA-Llama (Divide-Then-Aggregate Llama). First, we transform traditional linear and tree-based tool search paths into Directed Acyclic Graph (DAG) structures, generating a high-quality parallel tool invocation dataset. The DTA-Llama is then trained on the dataset to learn to iteratively divide the current task into several parallel tool invocation sub-tasks and aggregate the invocation results to decide the next actions. Furthermore, we introduce an efficient inference framework inspired by the Process/Thread mechanism when applying the DTA-Llama to practical tasks. Experimental results show that our approach substantially enhances task performance while reducing computational overhead and latency. We also achieve comparable to GPT-3.5's official parallel function-calling method.
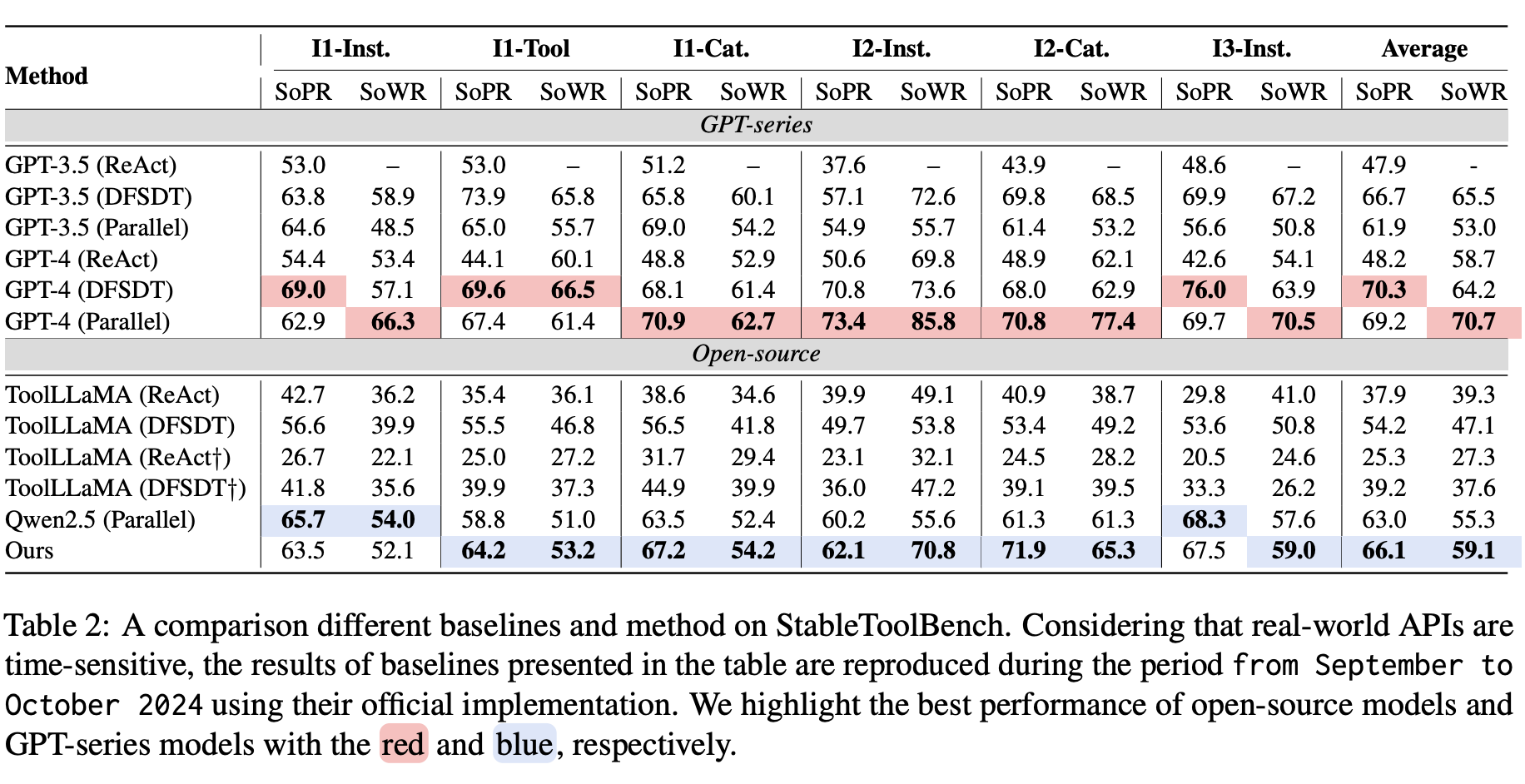
We conduct systematic experiments on StableToolBench, the most commonly used benchmark in the tool learning tasks.
SoPR measures the success rate of LLMs in solving tasks.
SoWR compares the quality of results against a GPT-3.5 (ReAct) baseline.
Success ✅
Success ✅
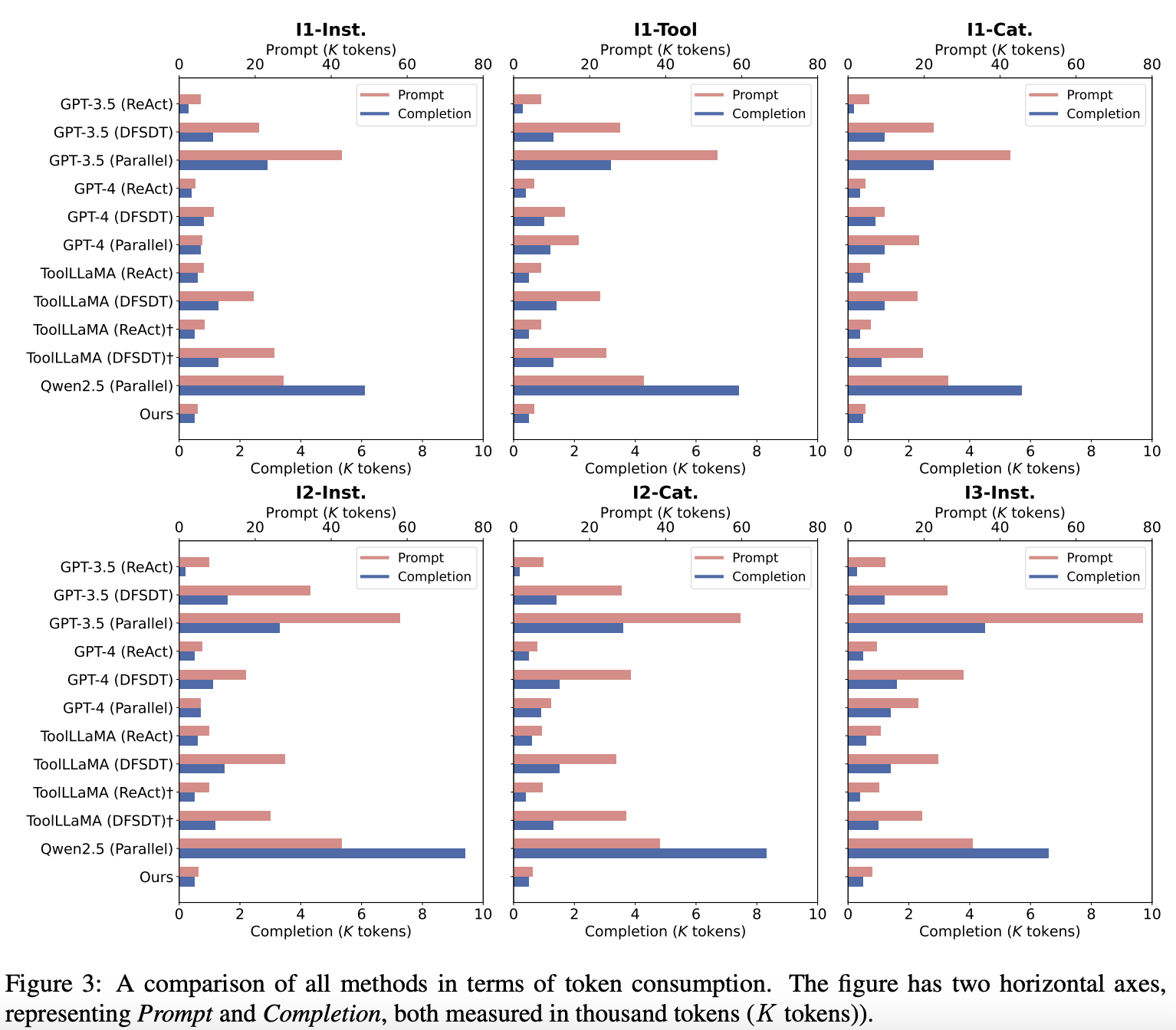
DTA can achieve better performance while saving your a lot of tokens (e.g., 5 times less).
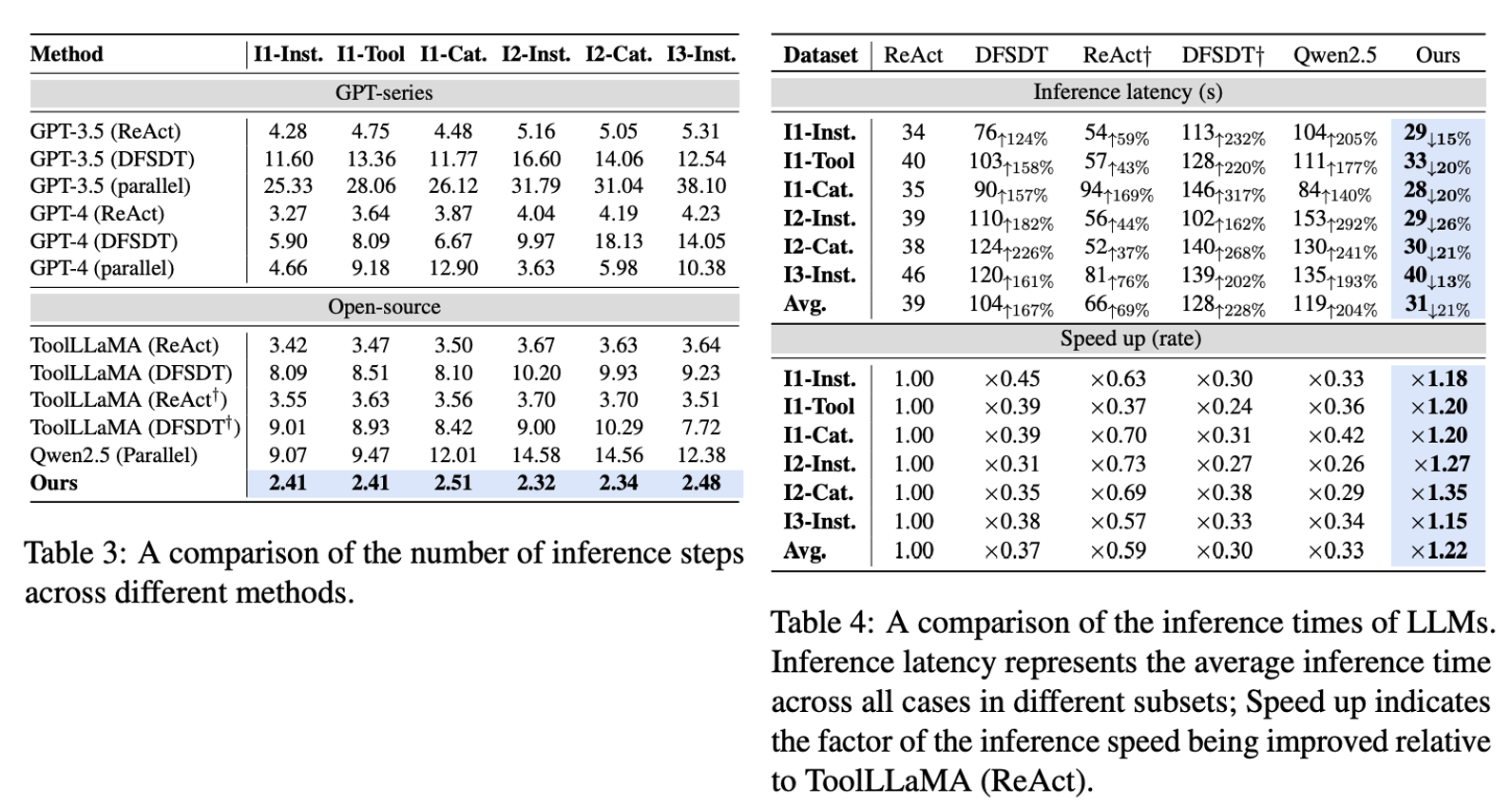
DTA can speed the inference time when manipulaing tools.
We thank prior work for their technique contribution, such as ToolBench and Llama-factory.
@article{zhu2025divide,
title={Divide-Then-Aggregate: An Efficient Tool Learning Method via Parallel Tool Invocation},
author={Zhu, Dongsheng and Shi, Weixian and Shi, Zhengliang and Ren, Zhaochun and Wang, Shuaiqiang and Yan, Lingyong and Yin, Dawei},
journal={arXiv preprint arXiv:2501.12432},
year={2025}
}